Hope I am not the only one this happens to.
Dream of building the greatest app ever, come up with a decent enough idea, research the available technology to build it and the data needed. Even gather said data and work on converting it to a suitable format. Then realise that it is 5am and you need to get up for work in the morning.
Anyways, in hopes that I help someone else out there kickstart their project. Here is a handy way to download the entire TFL london bus network, every route, GPS coordinates of every stop right to your doorstep.
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={1,10,100,101,102,103,104,105,106,107,108,109,11,110,111,112,113,114,115,116,117,118,119}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={12,120,121,122,123,124,125,126,127,128,129,13,130,131,132,133,134,135,136,137,138,139,14}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={140,141,142,143,144,145,146,147,148,149,15,150,151,152,153,154,155,156,157,158,159,16,160}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={161,162,163,164,165,166,167,168,169,17,170,171,172,173,174,175,176,177,178,179,18,180,181}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={182,183,184,185,186,187,188,189,19,190,191,192,193,194,195,196,197,198,199,2,20,200,201,202}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={203,204,205,206,207,208,209,21,210,211,212,213,214,215,216,217,219,22,220,221,222,223,224,225}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={226,227,228,229,23,230,231,232,233,234,235,236,237,238,24,240,241,242,243,244,245,246,247,248}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={249,25,250,251,252,253,254,255,256,257,258,259,26,260,261,262,263,264,265,266,267,268,269,27}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={270,271,272,273,274,275,276,277,279,28,280,281,282,283,284,285,286,287,288,289,29,290,291,292}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={293,294,295,296,297,298,299,3,30,300,302,303,305,307,308,309,31,312,313,314,315,316,317,318,319}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={32,320,321,322,323,325,326,327,328,329,33,330,331,332,333,336,337,339,34,340,341,343,344,345,346}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={347,349,35,350,352,353,354,355,356,357,358,359,36,360,362,363,364,365,366,367,368,37,370,371,372}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={375,376,377,379,38,380,381,382,383,384,385,386,387,388,389,39,390,391,393,394,395,396,397,398,399}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={4,40,401,403,404,405,406,407,41,410,411,412,413,414,415,417,418,419,42,422,423,424,425,427,428,43}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={430,432,434,436,44,440,444,45,450,452,453,455,46,460,462,463,464,465,466,467,468,469,47,470,472}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={473,474,476,48,481,482,484,485,486,487,488,49,490,491,492,493,496,498,499,5,50,507,51,52,521,53}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={54,549,55,56,57,58,59,6,60,601,602,603,606,607,608,609,61,611,612,613,616,617,62,621,624,625,626}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={627,628,629,63,632,634,635,639,64,640,641,642,643,646,647,648,649,65,650,651,652,653,654,655,656}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={658,66,660,661,664,665,667,669,67,670,671,672,673,674,675,678,679,68,681,683,685,686,687,688}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={689,69,690,691,692,696,697,698,699,7,70,71,72,73,74,75,76,77,78,79,8,80,81,82,83,85,86,87,88}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={89,9,90,91,917,92,93,931,94,941,95,953,958,96,965,969,97,972,98,99,A10,B11,B12,B13,B14,B15,B16}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={C1,C10,C11,C2,C3,D3,D6,D7,D8,E1,E10,E11,E2,E3,E5,E6,E7,E8,E9,EL1,EL2,G1,H1,H10,H11,H12,H13,H14}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={H17,H18,H19,H2,H20,H22,H25,H26,H28,H3,H32,H37,H9,H91,H98,K1,K2,K3,K4,N1,N11,N13,N133,N136,N137}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={N15,N155,N159,N16,N171,N18,N19,N2,N20,N207,N21,N22,N253,N26,N279,N28,N29,N3,N31,N343,N35,N38,N381}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={N41,N44,N47,N5,N52,N55,N550,N551,N63,N68,N7,N73,N74,N76,N8,N86,N87,N89,N9,N91,N97,N98,P12,P13,P4}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={P5,PR2,R1,R10,R11,R2,R3,R4,R5,R6,R68,R7,R70,R8,R9,RV1,S1,S3,S4,T31,T32,T33,U1,U10,U2,U3,U4,U5,U7}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
curl.exe "http://www.tfl.gov.uk/tfl/gettingaround/maps/buses/tfl-bus-map/dotnet/FullRoute.aspx?route={U9,UL1,UL2,W10,W11,W12,W13,W14,W15,W16,W19,W3,W4,W5,W6,W7,W8,W9,X26,X68}&run={1,2}" --create-dirs --output "busroutes\#1-#2.txt"
 I've applied several major updates to the tool discussed in this article. Update #1, Update #2, Update #3, Update #4 and Original post.
I've applied several major updates to the tool discussed in this article. Update #1, Update #2, Update #3, Update #4 and Original post. I've applied several major updates to the tool discussed in this article.
I've applied several major updates to the tool discussed in this article. 
 Since I created the
Since I created the  The small Météo France site I created has been updated with a new parameter that can be used to customize the unit that windspeed is presented as.
The small Météo France site I created has been updated with a new parameter that can be used to customize the unit that windspeed is presented as.



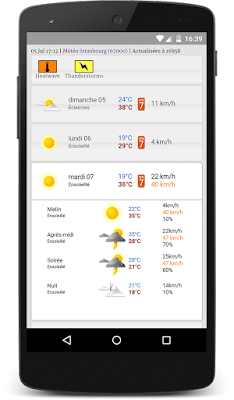 I've discussed the work I've done to build a simpler weather UI for the French météo service in earlier posts (
I've discussed the work I've done to build a simpler weather UI for the French météo service in earlier posts (








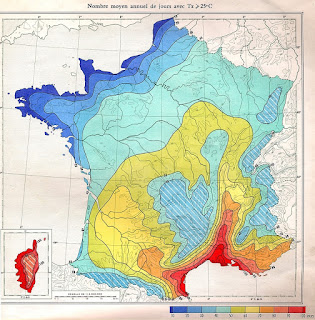 The
The 



 In an
In an  Realised today that I needed a good way to create a change list document for a small app that I am writing. The app has a few hundred screens, each of which is supported by a single data document that contains the information that the screen is showing.
Realised today that I needed a good way to create a change list document for a small app that I am writing. The app has a few hundred screens, each of which is supported by a single data document that contains the information that the screen is showing.